10 modèles de microservices que tu devrais connaitre en tant qu'ingénieur logiciel
Brève introduction à Circuit Breaker, API Gateway, BFF, Saga, CQRS, Event-Driven et plus encore.
Teacher -Software engineer- Digital strategist in Innovation and entrepreneurship - Github Campus Advisor
Pour créer des logiciels évolutifs, l'ingénieur/architecte logiciel doit choisir la bonne architecture, en particulier lorsqu'il s'agit de créer des logiciels/applications d'entreprise.
L'architecture monolithique est généralement le premier choix de la plupart des ingénieurs parce qu'elle est facile et qu'elle n'a pas à gérer la complexité des systèmes distribués, car une application entière se trouve dans la même base de code géante lorsqu'il s'agit d'une livraison agile de logiciels ; l'application monolithique n'est peut-être pas le bon choix parce que lorsqu'on apporte une petite modification au code, il faut re-déployer une application entière, ce qui peut prendre du temps, et l'autre chose est que l'on ne peut même pas mettre à l'échelle les composants/services individuels.
Une erreur dans un module, une fonctionnalité ou un service peut affecter la disponibilité de l'ensemble de l'application et c'est la raison pour laquelle l'architecture microservice vient à la rescousse.

Voici les 10 modèles de microservices que vous devriez connaître en tant qu'ingénieurs logiciels.
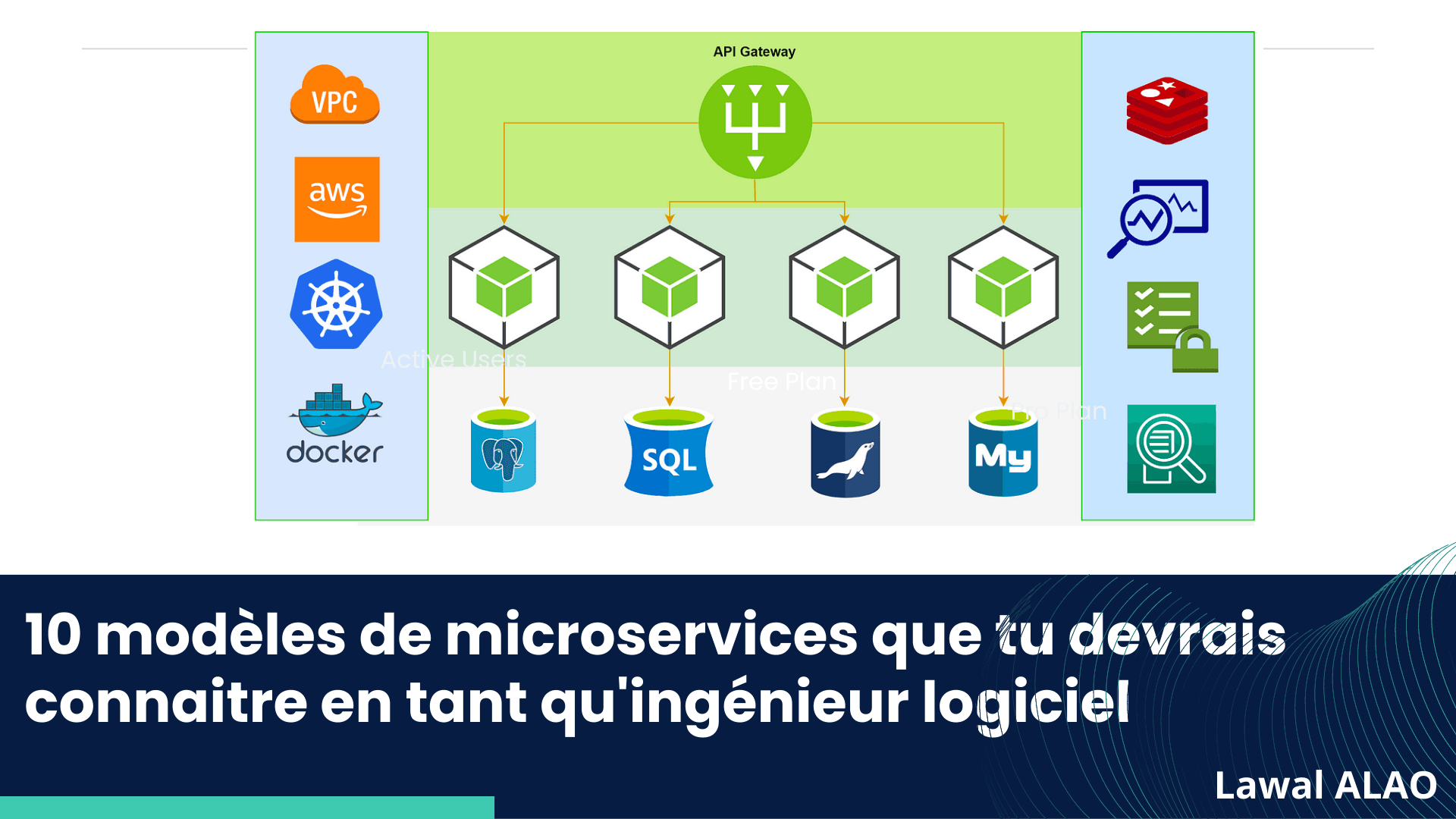
API Gateway : C'est le point d'entrée pour accéder à tous les microservices et nous pouvons mettre en œuvre des préoccupations transversales telles que la sécurité, la limitation du débit et l'équilibre de la charge. Nous pouvons utiliser Spring Cloud Zuul,Spring Cloud Gateway, Azure API Gateway (mais il en existe plusieurs) pour mettre cela en œuvre.
Service discovery: Il permet aux services de se retrouver par l'intermédiaire d'un nom plutôt que d'une adresse IP. Pourquoi pas l'IP ? Parce que l'IP change souvent au moment de l'exécution en raison de la fréquence à laquelle les conteneurs sont lancés et détruits. Nous pouvons utiliser Spring Cloud Eureka ou le service Kubernetes pour implémenter cela.
Circuit breaker ou Disjoncteur (lol) : Ce modèle est très utile pour traiter les erreurs transitoires. Par exemple, lorsque le service a appelle le service b et que ce dernier n'est pas disponible (dépassement de délai), il peut renvoyer un résultat de cache comme réponse par défaut ou se rabattre sur une requête à un autre service d'aide pour obtenir le résultat et permettre au service b de se rétablir sans essayer de lui adresser d'autres requêtes. Nous pouvons utiliser Hystrix ou Resilient4J pour faire cela.
CQRS : nous pouvons séparer les commandes-COMMAND (écriture) et les QUERY-requêtes (lecture), ce qui signifie que nous pouvons concevoir une table de base de données optimisant l'écriture et la lecture différemment pour l'extensibilité.
Bulkhead (tête de pont) : Ce modèle permet de gérer la tolérance aux pannes liée au pool de threads en divisant le pool de threads en fonction du nombre de services qui doivent être appelés. Par exemple, nous avons défini un pool de 50 threads dans le service A et le service A fera des requêtes aux services B et C. Donc, le service A devrait diviser le pool de 50 threads en 2 (25 pour le service B, un autre 25 pour le service C) de sorte que si le service C est indisponible ou prend plus de temps pour traiter la requête, cela n'affecte pas l'appel au service B parce qu'il a son propre pool de threads pour effectuer le travail. Nous pouvons utiliser Resilient4J pour faire cela.
Modèle axé sur les événements : Ce modèle permet un couplage lâche entre les services, ce qui signifie que les services n'ont pas besoin de se connaître pour communiquer. Le protocole de communication se fait généralement par le biais d'événements utilisant une file d'attente de messagerie telle que AMQP (RabbitMQ) ou Apache Kafka.
Saga : Comme nous le savons, il est difficile de gérer un système distribué, en particulier lorsqu'il s'agit de transactions distribuées ; le commit en 2 phases était la meilleure option, mais en raison de sa nature de verrouillage pessimiste, il est difficile de le faire évoluer, c'est pourquoi les modèles Saga entrent en jeu. Il y a plusieurs façons d'implémenter le schéma Saga : l'orchestration et la chorégraphie.
Le modèle Strangler : Il s'agit d'une manière de décomposer une application monolithique en microservices en extrayant progressivement chaque fonctionnalité de l'application monolithique en microservices individuels et en laissant l'application monolithique appeler ces nouveaux microservices à la place. Lorsque vous créez de nouvelles fonctionnalités, commencez par créer un nouveau microservice au lieu de créer cette nouvelle fonctionnalité à l'intérieur de l'application monolithique. L'extraction peut également inclure la création d'une nouvelle base de données pour ce nouveau service.
Sidecar : Probablement l'un des patterns les plus cool à connaître. Parce qu'il s'agit d'un moyen d'attacher des services transversaux en tant que sidecar au service métier proprement dit. Cela se fait généralement en déployant un service sidecar dans le même pod que le service métier réel.
Cas d'utilisation: communication sécurisée entre un service et un autre, mise en œuvre d'une journalisation ou d'une métrique. Nous pouvons utiliser le proxy Envoy comme sidecar.BFF : Également connu sous le nom de Backend for Frontend. La mise en œuvre de microservices pour chaque plateforme permet une plus grande personnalisation/optimisation en fonction de chaque plateforme. Par exemple, une application mobile peut ne pas avoir besoin d'images ou de vidéos de grande taille comme les applications web, mais il faut garder à l'esprit que le service peut être redondant.
CONCLUSION
Pour conclure, lors de la création de microservices, en tant qu'ingénieurs logiciels vous devriez envisager d'appliquer au moins quelques-uns de ces modèles afin de créer des logiciels évolutifs.
Si vous avez aimé cet article, n'hésitez pas à partager autout de vous et à laisser un pouce.